전체글
엔지닉 반도체 데이터 분석 스터디 29기 학습일지2
녹원
2025.07.16 19:30
조회 5추천 0스크랩 0
https://community.weport.co.kr/community/111951360
2일차는 데이터 유형의 종류에 대해 파악했다.
수치료 표현할 수 있는 수치형 데이터와 수치로 표현할 수 없는 범주형 데이터로 크게 분류된다.
그 중 수치형 데이터는 활률질량함수, p(x)로 표현되는 이산형 데이터와 확률밀도함수, f(x)로 표현되는 연속형 데이터로 세분화된다.

오늘은 이산형 데이터에 대해 공부했다.
이산형 데이터의 분포 종류에 따른 목적만 들었을 때는 개념이 정확히 와닿지 않았는데 예시와 함께 설명해주셔서 이해하기 쉬웠다.
- 베르누이 분포 : 1회 실험, 결과가 pass/fail 2가지
- 이항 분포 : n회 실험, 결과가 2가지
- 다항 분포 : n회 실험, 결과가 3가지 이상 (사건에 따른 확률p)
- 기하 분포 : 성공확률 p, n번째 시행에서 첫 번째 성공이 나올 확률
- 음이항 분포 : 성공확률 p, n번째 시행에서 k 번째 성공이 나올 확률 (2개의 독립변수)
- 포아송 분포 : 일정 단위당 희귀한 사건이 발생할 확률 (일정 단위 당 특정 사건의 평균 발생 횟수λ)
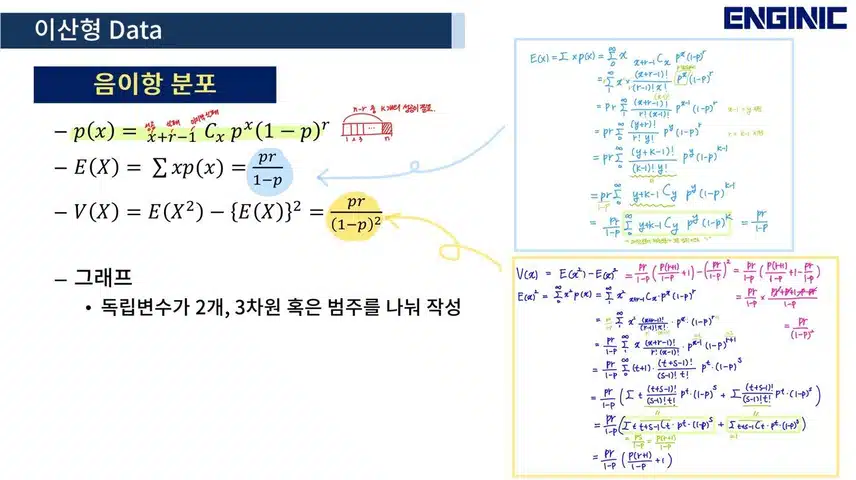
각 분포는 분석 목표에 따라 각각 다른 확률질량함수 p(x), 기댓값 E(x), 분산 V(x)의 값가진다.
이 값을 단순히 값을 암기하는 게 아니라 각 분포가 의미하는 바를 생각하며 유도하는 공식을 배울 수 있었기에 더욱 기억에 남을 것 같다.
신고하기
작성자 녹원
신고글 엔지닉 반도체 데이터 분석 스터디 29기 학습일지2
사유선택
 욕설/비하 발언
욕설/비하 발언- 음란성
- 홍보성 콘텐츠 및 도배글
- 개인정보 노출
- 특정인 비방
- 기타
허위 신고의 경우 서비스 이용제한과 같은
불이익을 받으실 수 있습니다.
댓글 0