엔지닉 반도체 데이터 분석 스터디 29기 학습일지1
녹원
2025.07.16 18:48
조회 6추천 0스크랩 0
https://community.weport.co.kr/board_EouY72/111948676
1일차에는 반도체 데이터 분석의 기초에 대해 배웠다.
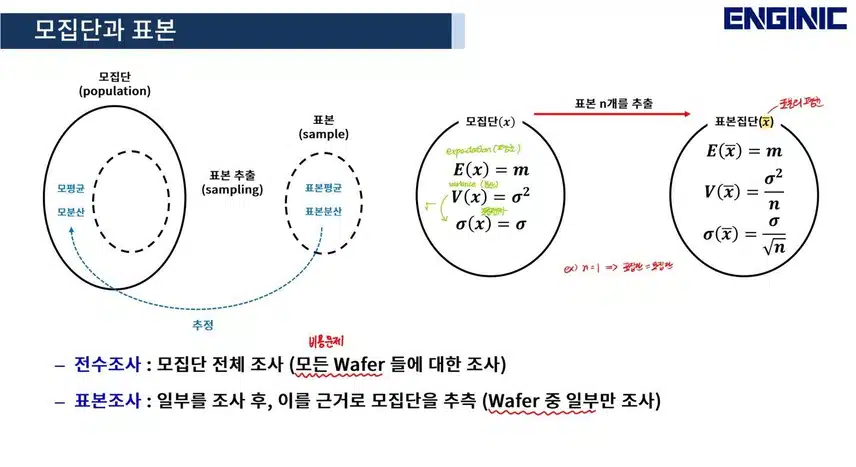
모집단과 표본에 대한 개념을 정리하고, 왜 반도체 데이터 분석시 표본조사를 해야하는지 비용이나 분석시 발생하는 반도체 질이 저하되는 등의 문제가 있음을 알 수 있었다.
data 수집시 유의사항 중 ‘전체를 대표할 수 있는가?’에 대한 설명으로 다이제스트와 갤럽의 조사 결과와 같은 실제 사례를 들어 설명해주셔서 어떤 의미인지 쉽게 이해할 수 있었다.
중심에 대한 정의 중 평균, 중앙값, 최빈수가 가장 많이 쓰이며, 산포의 종류 중 분산과 표준편차가 가장 흔히 사용된다. 논문을 읽다보면 box plot을 꽤 자주 봤는데 그게 사분위수 범위라는 것을 알게 되었다.
6시그마에 대해 스쳐지나가면 들어본 기억이 있는데 불량확률과 관련된 범위라는 것을 알게 되었고 기업에서 왜 6시그마 공정 기술을 확보하는 것이 중요하다고 하는지 이해할 수 있었다.

- 총 변동(S) : 편차의 제곱의 합으로 분산과 n을 곱한 값
- 자유도 = n-1
- 불편분산 : 표본 내에서의 분산, 총 변동을 자유도(n-1)로 나눈 값
1일차 강의중 가장 중요해 보이는 부분이다.
총변동, 분산, 표준편차, 자유도, 불편분산 등 여러 용어들이 튀어나오는데 남은 강의를 잘 이해하기 위해서는 용어를 혼동하지않도록 정의를 확실하게 알아두는게 중요한 것 같다.
신고하기
작성자 녹원
신고글 엔지닉 반도체 데이터 분석 스터디 29기 학습일지1
사유선택
 욕설/비하 발언
욕설/비하 발언- 음란성
- 홍보성 콘텐츠 및 도배글
- 개인정보 노출
- 특정인 비방
- 기타
허위 신고의 경우 서비스 이용제한과 같은
불이익을 받으실 수 있습니다.
댓글 0